关于自然语言转SQL
NL2SQL简介
NL2SQL是将自然语言文本转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析的子任务。
NL2SQL的流程步骤可能包括以下几个方面:
- 问题理解:分析问题的意图、结构、逻辑、关键词等,提取出问题中的实体、属性、条件、操作等信息。
- 表格理解:分析表格的结构、格式、领域等,提取出表格中的列名、行名、值、类型等信息。
- 模式映射:将问题中的信息和表格中的信息进行匹配,确定查询的目标列、条件列、条件值等。
- SQL生成:根据模式映射的结果,生成合法且正确的SQL语句,可能涉及到多表连接、子查询、聚合函数等操作。
NL2SQL的存在的难点可能包括以下几个方面:
- 问题复杂性:问题可能涉及到多个步骤、逻辑、比较、聚合等操作,需要深入理解问题的含义和需求。
- 表格多样性:表格可能有不同的结构、格式、领域等特征,需要泛化到未见过的表格上。
- 模式映射:问题中的信息和表格中的信息可能有不同的表达方式、缩写、别名等,需要进行有效的对齐和消歧。
- SQL生成:生成的SQL语句需要符合语法规则且能正确执行,需要考虑不同数据库系统的兼容性和效率。
大模型对NL2SQL的影响
Spider榜单目前的第四名是基于codex实现的(得分78.2),第一名是基于GPT-4实现的(得分85.3分),从分数上看,GPT4实现的得分与第二名79.9分差距十分明显,codex实现相对第二名落后并不大。
![]()
由此可见大模型在NL2SQL里具备技术优势,其泛化能力和迁移能力结合预训练数据训练通用的领域知识及数据库知识,使其可以到达当前最高的水准。
在实际使用过程中,交互性的对话能力,可以通过用户上下文的反馈学习,取得更符合目标的结果。
NL2SQL应用场景
大模型并不是万能的,其具备以下问题:
- 可复现性,每次生成的结果可能不稳定
- 可解释性,难以理解如何得到的结果,是否存在歧义及错误
- 可靠性, 其可能并不理解用户的真实需求,或者SQL的语法规则,只是单纯在模仿
另一个局限性来自自然语言本身,自然语言无法代替SQL的严格性和精确性语言本身存在表达不准确或者认知偏差。
因此单纯依靠自然语言直接得到SQL并执行的方案存在限制,但是可以作为SQL的补充,对其定位为辅助场景,帮助没有SQL编写经验的业务人员可以灵活的进行个性化的取数需求。考虑到这个领域已经有大量的低代码工具,如何和这些工具结合是一个思考方向。
可以参考开源项目 sqltranslate(基于模型code-davinci-002)及 工具服务sqlkiller(实现未知)。
简单测试用例设计
要素考虑
- 表结构信息是否可以理解
- UDF用户定义函数及其他数据库特有的系统函数
- 数据库方言能否处理
- 模型token使用量考虑
- 回答的逻辑是否符合(条件判断是否正确)
- 语言中的隐含信息是否可以提取
- 是否支持多表关联查询
- 是否列出了指定的列
- 是否按照正确的方式进行排序
- 是否使用正确的统计函数
用例
用例尽量不要用公共测试集一样的SQL,可能已经被训练过了,会影响最终的评价,最好自己设计或者使用公共数据集但修改一下用例
简单例子可以参考databend里的ai_to_sql的例子
- 统计年龄大于30岁的美国用户2022年全年期间的订单累计消费金额及订单总数,根据他们的名字排序
- (补充)统计所有中国青少年的全部订单数
模型选择
考虑的要素:价格、生成方式(提示语)、响应时间、生成的质量。
gpt-35-turbo、text-davinci-003、code-davinci-002、GPT-4 从目前看都具备不错的效果,但这些模型的使用成本是不同的,而且模型本身有专注于不同的任务。
其中gpt-35-turbo、GPT-4主要是对话式的,对于生成SQL的场景不大需要其对话能力和处理通用问题的能力。
code-davinci-002(codex) 主要强项在代码生成,SQL对于代码来说相对简单,也是比较贵的模型,1000token高达0.1 刀的成本并不适合作为SQL生成的方案。
GPT-4同样问题也是贵,综合看来,选择text-davinci-003或者干脆考虑性价比最高的gpt-35-turbo。
提示语工程
提示语工程是一种利用自然语言生成技术,为用户提供合适的提示语,帮助用户更好地表达查询意图的方法。提示语工程对NL2SQL的意义在于,可以提高用户输入自然语言问题的质量和准确性,从而提高SQL生成模型的性能和鲁棒性。提示语工程也可以帮助用户更好地理解数据库的结构和内容,避免一些无效或错误的查询。
不同的模型对于提示语的要求是不同的,如codex要求将需求写成注释的形式,如下所示:
### PostgreSQL SQL
# {table_ddl_1}
# {table_ddl_2}
### {prompt}
SELECT
对于对话类的模型如gpt-35-turbo,需要类似角色扮演的提示语:
- 系统提示语
- 用户提示语
例如:
system_prompt = f'You are a PostgreSQL database with the following table structure. \
Your answer can only be SQL. If the table structures cannot fulfill your answer, \
please respond with "The database does not contain the table data you are looking for : ) "\n{table_ddl}'
user_prompt = f'Please answer me briefly with SQL code, just sql content: {prompt}'
关于表结构的定义方式目前测试的两类都满足,一种是直接按照建表语句:
CREATE TABLE users(
id INT,
name VARCHAR,
age INT,
country VARCHAR
);
CREATE TABLE orders(
order_id INT,
user_id INT,
product_name VARCHAR,
price DECIMAL(10,2),
order_date DATE
);
另一种是用另一种形式化的表达方式如:
Table users,colums=[id,name,age,country]
Table orders,colums=[order_id,user_id,product_name,price,order_date]
基于某开源项目进行效果实测
主要通过sqltranslate跑; sqlkiller 看起来挺不错的,但没开源也就没去测试了; sqlchat提供了一种对话式的交互方式,使用的也是gpt-3.5-turbo模型,同时支持生成的SQL执行并返回结果。
一些测试结论
- 提示语对SQL生成的精确度有直接影响,模型的质量也很重要
- 表字段的含义可以通过注释语句说明
- SQL特有的UDF也可以通过提示语说明,亦可以加在表结构申明里,但不要用创建函数的语句,而是要说明函数及其用途
- 方言也可以在提示语里解决,但模型是否支持是前提
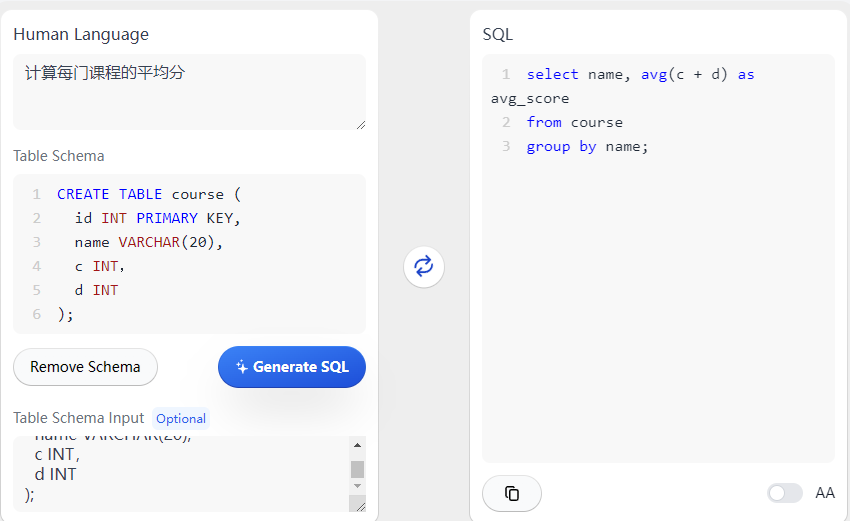
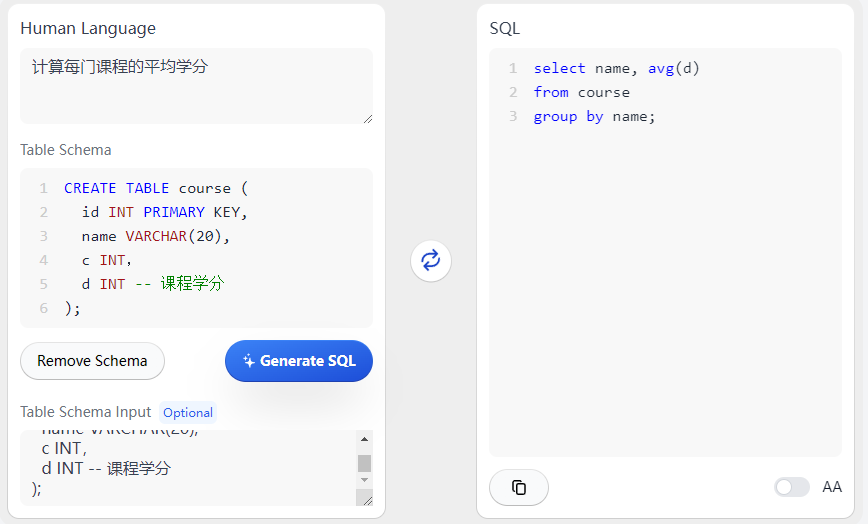
- 目前对于潜台词的理解并不完美,比如关闭时间,其实隐含了从开启到关闭的时间,更准确的说法是持续时间…而且这个用例里有一个隐藏条件,是统计已关闭的;还比如注释写学分,提示语平均分是无效的,需要写平均学分
后续工作
如何评估方案的效果、评估标准及工具设计。(基于开源的NL2SQL基准测试集,设计效果评测方法及脚本工具。如Spider、SParC等)
对用户进行如何更好的编写提示语的培训,双向奔赴,完善写SQL的效果。
参考资料
- Spider
- wikitablequestions
- SParC
- sqltranslate
- sqlkiller
- Azure OpenAI models
- Azure OpenAI codex usage
- natural-language-to-sql-codex
- sqlchat